Josef Troch (troch@mail.ru)
28.3.2000 (poslední změna 5.4.2000)
Algoritmus ACB
- Associative Coder of Buyanovsky
- velmi efektivní bezztrátová metoda (ale celkem pomalá) především na kompresi textu
- adaptivní jednoprůchodová metoda; k určení následujících znaků je použito několik znaků předchozích
- celkem dobře znatelná souvislost s LZ77 a LZ78
- aktuální implementace (by George Buyanovsky) - ACB verze 2.00c pro DOS (Shareware) ftp://ftp.elf.stuba.sk/pub/pc/pack/acb_200c.zip
- přesné detaily fungovaní algoritmu (či zmíněné implementace) jsou stále neznámé
Metoda používá posuvné okno (sliding buffer) podobně jako algoritmus LZ 77.
Příklad:
Předpokládejme, že text "...swiss miss is missing..." je část vstupního řetězce a že
prvních 7 symbolů jsme již zpracovali a jsou nyní v prohlížecím okně (search buffer). Aktuální okno (look-
ahead buffer) začíná textem "iss is...".

kontext(context) content(následující text)
Kontext je v každém okamžiku to, co již bylo zakódováno, text, který za ním následuje se nazývá anglicky
"content". Text je postupně kódován a všechny kontexty (vždy posun hranice kontext/content o 1
znak) jsou dávány do slovníku budovaného v paměti, každý vždy s příslušným "následujícím textem"
(content).
Následující obrázek 2a) znázorňuje 6 položek slovníku odpovídajících 7 již přečteným
symbolům.
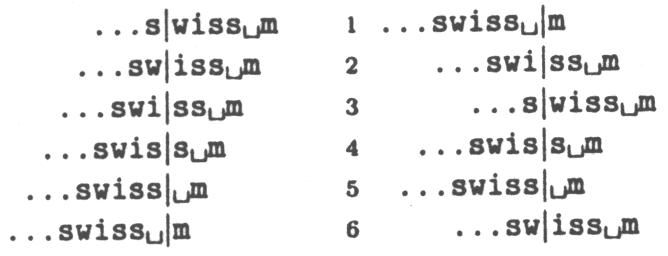
Obrázek 2 a) b)
Slovník je pak setříděn podle kontextů (resp. nové položky jsou do něj zatříděny) - kontexty třídíme od
konce zpátky, tedy zprava doleva! Výsledek pro náš příklad je na obrázku 2b).
Kontext i content by měly být co nejdelší, ale mohou obsahovat jen symboly ze search bufferu (protože
look-ahead buffer je pro dekoder neznámý).
Tímto způsobem enkoder i dekoder vytváří i updatují své slovníky.
Enkoder
Algoritmus:
- Aktuální kontext (zde "...swiss m") je porovnán s položkami
slovníku (jejich kontextovou částí) (opět zprava doleva).
V našem příkladě akt. kontext padne mezi
2 a 3 - předpokládejme, že algoritmus zvolí 2.
- Aktuální content je porovnán s contenty položek slovníku (normálně - zleva doprava).
Zde nejlépe odpovídá řádek 6; 4 znaky se shodují.
Tady ovšem vyhledávám v nesetříděném - pomalé, ale asi se mohu omezit na dosti blízké okolí nalezeného
kontextu (viz dále).
- Na výstup zapíšeme trojici [d,l,x] - kde d je vzdálenost nalezeného
nejpodobnějšího contentu a nejvíce odpovídajícího kontextu (může být záporná), l je počet
shodných písmen (chceme co největší, ale může být 0) a x je následující (1. neshodující se)
znak v look-ahead bufferu (jako u LZ 77).
Zde tedy zapíšeme: [4,4,"i"]
- Updatujeme slovník.
Pětice zkomprimovaných znaků (tedy text "iss i") je tedy připojena ke všem položkám
slovníku (do části content) a je posunuta do search bufferu. Tato pětice zároveň způsobí přidání 5 položek
do slovníku - obrázek 3a) (po setřídění 3b) ).

Obrázek 3 a) b)
Nové posuvné okno(sliding buffer) bude vypadat takto:

Nejpodobnější kontext bude nyní mezi položkami 2 a 3 - předpokládejme, že algoritmus zvolí 3.
Nejpodobnější content má položka 8 ve slovníku - shoduje se v 6 znacích. Na výstup tedy zapíšeme
[5,6,"i"] - odpovídá to 7 znakům (tyto připojíme ke všem položkám slovníku a posuneme do search
bufferu).
7 nových položek se přidá do slovníku (nesetříděný - obrázek 5a), setříděný 5b) ).

Obrázek 5 a) b)
Nové posuvné okno(sliding buffer) bude vypadat takto:

Nyní budou nejpodobnější položky pro kontext 6 a 7 - předp., že algoritmus zvolí 6, ale žádný content ve slovníku se neshoduje s aktuálním ani v 1 písmenu. Tedy zapíšeme [0,0,"n"]. Tato trojice tedy způsobí prodloužení souboru.
Konec příkladu.
Dekoder
Staví a updatuje slovník zcela stejně jako enkoder (tedy ho mají v každém kroku stejný).
Algoritmus:
- Protože dekoder má data ze search bufferu, najde nejlepší výskyt aktuálního kontextu ve slovníku (označme tuto položku t)
- Načte trojici [d,l,x]
- Vezme d+t - má index nejpodobnějšího contentu ve slovníku
- Okopíruje z něj l symbolů na výstup a zapíše též x
- Updatuje si slovník
Slovník
Slovník může být implementován jako seznam pointrů do search bufferu:
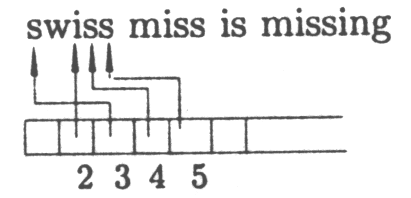
Výše znázorněné pointry nám stačí k identifikování příslušného kontextu i contentu (stačí si někde
bokem pamatovat pointer na začátek search bufferu a na konec search bufferu).
Modifikace
Místo trojic je možno zapisovat jen dvojice [vzdálenost, délka shodného úseku = l], pokud l=0
zapíšeme přímo kód znaku (ASCII hodnota), jinak dvojici. Toto si samozřejmě vynutí před každou
dvojicí/ASCII hodnotou zapsat bit, udávající co následuje. (Analogie k LZSS.)
Velká část efektivity tohoto algoritmu je přičítána způsobu jak enkoduje vzdálenost d a délku
shody l. Detaily tohoto, ovšem nejsou známy.
(Pozn.: Podle mého názoru - povolíme-li d jen dosti malé (rozsah 16? 64?), mělo by to v typickém případě
vést ke zkrácení souboru.)
Vylepšení metody ACB
Jedná se o určitou obměnu metody ACB, která je pomalejší, vyžaduje určité třídění před zakódováním další
skupiny znaků, ale je efektivnější.
Příklad:
Předpokládejme tento řetězec v posuvném okně:

Označíme tento řetězec S.
Část aktuálního slovníku (setříděná dle kontextu jako obvykle) je na obrázku 9a).

Obrázek 9 a) b)
Prvních 8 a posledních 5 položek jsou z konce aktuálního search bufferu, 10 prostředních je starších.
Algoritmus
- Všechny položky slovníku, které se v alespoň k-symbolech (v našem příkladě k=9)
shodují s akt. kontextem vybereme a vytvoříme z nich asociativní seznam (obrázek 9b) )
Všechny tyto položky mají kontexty podobné aktuálnímu.
- Nyní setřídíme tento seznam ve stoupajícím pořadí podle contentů (normálně - zleva doprava).
Pro náš případ toto znázorňuje obrázek 10a)
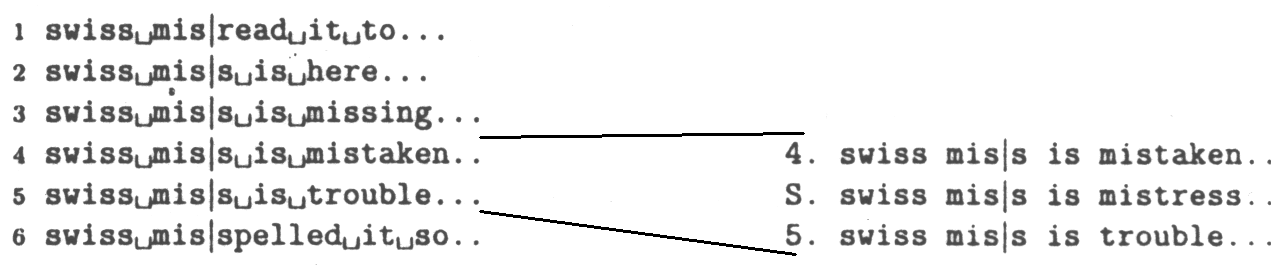
Obrázek 10 a) b)
- Zjistíme, mezi které položky nám padne řetězec S.
(zde mezi 4 a 5 - obrázek 10b) )
- Protože tyto tři položky jsou setříděné, můžeme je brát jako bitové řetězce - viz obrázek 11a)

Obrázek 11 a) b) c)
Vysvětlivky: - "xx...x" jsou (maximální) bitové řetězce, ve kterých se shodují
všechny 3 řetězce.
- "zz...z" jsou další bity, ve kterých se shodují položka slovníku 4
a řetězec S
(Případy a) a b) jsou možné případ c) nemůže nastat(nastal by spor se setříděností).)
- Zapíšeme na výstup trojici [index předch. položky před S po setřídění =m, "podtržený
bit"=b, délku l řetězce "zz...z"]
Tedy zde [4,1, l].
Dekoder vytvoří stejný asociativní seznam, setřídí ho, přečte trojici, najde maximální shodu
mezi m a m+1 položkou a zkopíruje ji na výstup, přidá bit (b xor 1), použije l
ke zjištění části "zz...z", tuto zkopíruje na výstup a přidá bit b.
- Problém s hranicemi bajtů (podle mě je asi nejlépší řešení, aby vždy enkoder nakopíroval na
výstup všechny bity až na hranici 1. bajtu - dekoder triviálně)
- Vylepšení:
- zapisovat místo l jen počet bitů (b xor 1)
- mazat shodné položky v asociativních seznamech
- Context files
Pozn.: Vyhledání položek se stejným kontextem jako je aktuální, jejich setřídění, zatřídění S a bitové
operace způsobují pomalost.
Pokud má dojít k "slušné" kompresi je třeba velký slovník.
Literatura:
- Salomon D. - Data Compression, 1997, Springer, New York.
- Buyanovsky G. - Associative Coding, Monitor, duben 1994 Moskva, č. 8, str. 10-19 (rusky)
- Fenwick P. - Symbol Ranking Text Compression, Tech. Rep. 132, červen 1996, Dept. of Computer Science, University of Auckland, New Zealand
Pozn.: Tento referát byl vytvořen s použitím knihy (1.); i všechny použité obrázky pochází původně z této
knihy.
Tento článek smí být používán libovolně, za předpokladu, že nebude modifikován a že takto
bude učiněno se zmínkou o autorovi a odkazem na stránku
http://jt.sf.cz, odkud by měla být dostupná aktuální verse tohoto
článku.
Snažím se, aby informace zde uvedené byly pravdivé a pokud možno přesné, nicméně nenesu žádnou
odpovědnost za to, že tomu tak opravdu je, ani za jakékoli škody, které by někomu v důsledku případných
špatných či nepřesných informací z tohoto článku mohly vzniknout.
Pokud se Vám podaří tento algoritmus implementovat, zkuste mi poslat Váš výtvor - předem děkuji.
Jakékoliv dotazy či připomínky mi můžete poslat mailem.
Zpět na stránku referátů a programů